










近日,Pivotal公司将把旗下大数据套件中的主要组成部分加以开源与其他一些软件公司共同成立名为Open Data Platform(即开放数据平台,简称ODP)的数据开放平台。据了解目前ODP的白金成员中包括Pivotal、通用电气、Hortonworks、IBM、Infosys、SAS以及某家“大型国际化电信企业”。除此之外,AltiScale、Capgemini、CenturyLink、EMC、Splunk、Verizon企业解决方案、Teradata以及VMware则以金牌成员身份列席。
本次Pivotal开源的三个组件分别是:
-
GemFire 分布式内存数据库
-
HAWQ 大规模并行SQL on Hadoop分析处理引擎
-
Greenplum DB 大规模并行处理分析数据库
作为一个专门为企业级用户服务的公司,Pivotal将其大数据套件的三个核心组件开源,背后到底隐藏着什么?CSDN本着打破沙锅问到底的精神采访了Pivotal大中华区总经理刘伟光,听听他对于本次事件的解读。
 Pivotal大中华区总经理刘伟光
Pivotal大中华区总经理刘伟光
用互联网思维做企业级市场
见到刘伟光的时候已经是下午将近四点钟,他刚刚从公司的内部会上下来,显得很是疲惫。不过当他谈起Pivotal本次开源的事情,感觉整个人仿佛都充满了活力。 他谈到Pivotal骨子里充满了互联网的基因,成立的初衷也是希望可以利用具有互联网技术基因的软件产品来帮助企业级用户打造企业级云和大数据平台,满足企业级客户的要求。 因此要将自己本身优秀的技术在全球进行推广和分享,同时将其他优秀的技术结合进来为客户快速的提供更加完整的解决方案,开源将是最行之有效的做法,。开源以后可以通过社区的力量以及客户的的大规模使用和实践来不断完善产品,从而形成一个更加完整放以及不断升级的数据平台。
谈到本次的ODP计划,刘伟光表示:“这是一个伟大的开放数据的生态环境,也是软件行业的一个创新发展,,因为目前没有任何一家公司可以将云和大数据所涉及全部需求都覆盖掉。ODP的产生就是为了将Hadoop和大数据技术聚集,而发展出来共同推出的数据核心平台,这个平台将会从数据的核心技术应用出发,加速整个生态系统的开发,对这些产品、技术进行整合,为客户提供真正企业级的平台,同时满足企业所需要的各种能力和需求。” 对于企业来讲 ,未来不需要再去考虑选用哪些商业化的软件产品进行组合集成后来构建平台,他们有了更多的选择,在有足够自有技术力量的保障下,它可以在这个平台上选择很多开源技术,同时这些技术可以进行自由组合,满足企业的个性化需求。 同时对于开发者来说 ,通过ODP,开发者可以去自由的使用和访问更多优秀的代码,掌握更多的开源技术为企业需求服务,另外一方面,尝试选择和使用一些新的技术,实际上对开发者和使用者来说选择构建数据平台的技术的时候也开辟了另外一个选择的空间,学习先进技术的同时也可以将自己在此基础上推陈出新的代码回馈给社区。
什么是Pivotal本次开源计划的真正杀手锏? 那就是这些即将开源产品已有的市场认知度,很多我们耳熟能详的开源软件,他们的诞生就是从开源社区一点点发展起来。而我们开源的产品都是在市场上被大量企业客户成功实践,久经考验的商业化软件,本次开源计划极大加速这些软件在全世界市场的普及,也会在中小市场以及生态链上对竞争对手产生一定的影响。
CSDN:对于ODP成员的选择有要求吗?
刘伟光:目前ODP刚刚成立,没有一个定性的要求,可以说是处于一个比较开放的状态,也可以说是一个海纳百川的状态。我们希望致力于大数据、云计算等数据相关的公司以及自由组织都可以加入进来。将自己最好的技术贡献出来,与其他的技术做集成,我们希望在加入ODP以后,多种技术直接可以做到真正的打通、融合,可以让数据在这些软件平台间真正的高效运转起来。我们今天可以大胆的预言,在未来,某个公司的单一产品无论多好可能都会逐渐失去市场的份额,因为开放的技术联盟将打破传统游戏规则,客户更希望选择已经ready的最好的技术的组合和无缝集成,而不是自己通过第三方公司或技术进行集成。就像今天在ODP当中Pivotal和Hortonworks的强强联合,业界最好的SQL On Hadoop分析处理引擎与最好的Hadoop技术强强联合,为客户提供了一个满足大型企业要求的高效的大数据解决方案,这种技术联盟必将会立刻吸纳更多的客户开始选择并实践。
CSDN:Pivotal开源的三个产品Greenplum, HAWQ, GemFire都是目前企业有强大需求的大数据领域,为什么选择把这三个产品开源?是否是100%开源?
刘伟光:其实Pivotal从去年下半年的时候,公司就开始了启动了业务模式的转型。从一个卖大数据和PaaS平台的软件公司,转向一个全面拥抱开源的软件公司。让我们来分析其转型的深层次原因,从技术推广的角度看,单一的商业软件销售模式属于上一个时代,在今天即使有100个Pivotal公司的规模也很难将自己的技术迅速在全世界进行推广。这个不是技术本身的问题,而是一个技术和业务模式的问题。而软件的开源模式推出后,全世界的开发者和使用者可以第一时间去使用和实践我们的技术。同时可以以社区的方式进行代码的优化和完善,进而反馈给社区,换个角度看其实是把一个封闭的软件开发模式变成了让全世界的技术人员都可以一起参与开发优化测试的新的业态。因此我们希望可以通过开源,将我们优秀的技术与大家共享,让大家可以了解和使用它。其实我们看我们Pivotal的Cloud Foundry的发展路径就是沿着上述方式发展起来的,短短几年间Cloud Foundry 已经拥有大量成功应用的案例,在国内,百度和京东两大互联网和电商公司的使用就是一个很好的例证。在今天我们看到无论是IBM,HP,华为都在广泛的使用我们Cloud Foundry技术来构建他们的云平台,而Cloud Foundry的迅猛发展正是得益于开源的力量,而Pivotal在发展开源社区的同时也积累了很多企业客户的需求从而构建了Pivotal Cloud Foundry的版本,满足那些有高要求的私有云,混合云和公有云客户,也就是我们面向企业客户的商业版本,所以开源和商业版的发展其实就应该是这一种彼此促进的发展形态。
本次开源计划的具体落地将会发生在今年的下半年,但是Pivotal在开源的同时我们还会继续推出我们的商业版,也就是说我们的各个软件商业版本涵盖企业级客户所需要的技术和功能模块,这部分代码不在本次开源的计划当中,我们会随后公布我们的具体的实施计划。可以肯定的是,其中最大的区别就是商用版会有一些企业用户特别需要的功能,例如监控管理,弹性收缩,安全管理,性能管理,高可用性支撑等等,同时商业版的用户可以得到Pivotal原厂的技术支持,包括故障解决,软件升级,性能调优,系统巡检等等,而这些服务并不针对是开源版本的使用者。。
开源不等于免费
CSDN:Pivotal是面向企业级应用的软件企业,而这些企业级的用户目前大多在使用IOE的产品和服务,他们对开源的接受程度会怎样?
刘伟光:其实最近十年中国的软件行业在不断的变化和发展,市场对于开源的态度也发生了很大的变化。互联网企业的成功也大大推动了开源的发展,同时也证明了开源的技术在强有力技术团队的保障下是可以构建大型的系统和应用平台。 以前企业级用户不选择开源产品我认为主要有以下三个原因:
第一,以前开源产品的功能不够完善,性能具有很多瓶颈,无法去支持企业级的用户需求,尤其是中国的大型企业,诸如电信,金融,政府等等。
第二,很多的企业拥有自己固有的采购流程和规则,习惯于将软件的采购变为企业的固定资产,这是一个非技术问题,所以这个过程当中,他们更希望去购买那种商业版本的软件,这种软件不但能够让你拥有该软件的永久使用权,也能变成企业的固定资产。,同时能够得到一个原厂公司正规的商业化支持,尤其在产品出现问题,出现Bug的时候,这些企业必须得到原厂的这种技术支持。所以这是我觉得这是很多公司不能去选择开源的一个最重要原因。
第三,你看目前国内哪些公司在用开源,都是一些大的互联网企业。为什么?道理其实很简单,因为使用开源技术必须有一支技术能力非常强的团队,这样才能够不依赖第三方公司,自由的的去使用开源软件来构建自己的平台,并且在上面不断的构建自己的功能模块。这也是为什么像BAT他们可以使用开源而不是购买商业软件也可以成功的重要原因。
不过通过这几年的变化可以看出来,互联网企业和传统企业正在逐渐的融合。传统企业的业务应用越来越复杂,要求集成许多不同的流程、应用程序和技术,而且传统企业都在拥抱互联网,O2O的蓬勃发展就是一个最好的例证。。传统的软件的许可证采购模式也限制了选择和增加了成本。转向开源软件技术有助于缓解这些问题和加快应用以及企业应用。目前越来越多的开源软件已经成为企业级IT的一个主要成分。同时开源社区的迅猛发展,也使得开源软件解决方案很容易找到和很容易实施,许多架构师和开发人员都熟悉这个技术的架构。开源软件团体推动开源软件开发人员提供使用方便的框架和平台。许多经过验证开源软件解决方案还能够让企业以最小的成本迅速创建应用,应对市场的变化。未来的大型企业市场将是一个商业软件和开源软件共存的生态环境。
CSDN:本次开源以后的商业模式将会如何?对于客户来说他们获得的服务质量如何来保证?
刘伟光:Pivotal这次开源计划以后的销售策略其实是有两种。一种是订阅License(许可证),就是我们的软件商业版本。同时我们也保留以前永久License销售模式,针对一些特定的客户群体。对于Pivotal提供的服务来说,跟具体license(许可证)形式没有关系,只要客户在Pivotal软件许可证的范围内,我们都会一如既往的提供高质量的企业级服务
CSDN:企业过渡到这套企业大数据平台上的挑战?
刘伟光:其实这些过渡我们都可以帮助用户很简单的解决。例如,除了12306之外,Pivotal的技术在中国的市场呈现用户数量激增的状态,其中不乏像百度、京东、携程、海尔和中航信,中国移动,中国联通,德邦物流,顺丰速递,建设银行,平安银行,太平洋保险,中信证券,国泰航空,台积电,国家超级计算中心,华为等等等。在中国扎根,自然离不开本地生态系统的培育。作为一家平台层的软件平台提供商,Pivotal不仅和国内主流的软件开发商和系统集成商建立战略联盟关系,同时也担当起在硬件厂商和云服务提供商之间“承上启下”的角色。现在的企业需要灵活性和创新,Pivotal大数据套件同时满足了这两种需求。同时本次开源后套件提供的一系列功能与订购模式相结合,使客户既能够运用所需技术,又不会受到传统许可方式那样的限制。是一种帮助客户促进数据增长、降低风险的全新方式,使客户能够蓬勃发展、实现创新。
在实现大数据真正为企业所用的征途中,Pivotal大数据套件是一个重要的里程碑。Pivotal HD、HAWQ、Greenplum数据库和GemFire这些软件的商业版本,加上之前已经在Pivotal旗下的Redis,Rabbit MQ开源产品,我们将为整个市场贡献开发新一代数据基础架构解决方案所需要的全部组件。开放这些组件的源代码将有助于加速客户采用这些组件,提高创新速度。Pivotal大数据套件除了已提供的基于裸机、一体机以及虚拟化软件交付方式之外,现在增加对公有云、私有云及混合云的支持。此外,通过内置的Pivotal Cloud Foundry运行管理器,还可以将Pivotal大数据套件作为PaaS服务,将大数据的能力提供给基于Pivotal Cloud Foundry的应用,也就是企业的PaaS平台,所以Pivotal大数据套件2.0版本跟上一版本最大的区别就是具有与云计算平台结合的基因。
做企业级PaaS应用布道者
CSDN:从以往的经验来看,互联网公司或者专门做开源的公司开源出来的产品往往会发展的比较好,而企业级软件公司开源出来的产品往往社区会非常不活跃,你们该如何处理这些问题?
刘伟光:这也是我们思考的一个问题,因为现在ODP生态环境才刚刚开始建立。不过我们在CloudFoundry社区发展上积累了很多经验。每年我们将会举办一系列的活动,这些活动和商业无关。
-
第一,我们会定期的在线举办一些社区活动,让开发者参与进来,增加用户的粘性与社区活跃度。
-
第二,我们计划在2015年搞一个比较大的活动,联合全国的高校举办第一届CloudFoundry开发大赛,同时联合一些大的企业和机构参与进来一起推动,希望将最好的PaaS技术普及到所有的开发者当中
-
第三,我们会搞一些大型的社区回馈活动,比如说通过社区之星活动,选拔一些社区里比较活跃的人物,对他们进行奖励等等。
-
第四,我们准备今年出一本有关企业PaaS之路的书,希望可以将PAAS技术Cloud Foundry推广出去,Pivotal希望成为一个企业PaaS的在布道者和领导者。
CSDN:HAWQ和其他SQL on Hadoop系统,例如Impala, Drill, Tajo, Presto有哪些区别?对于不同的用户该如何选型?
刘伟光:HAWQ是在Hadoop上一个大规模节点上通过SQL进行数据分析的好方案。这是Pivotal HD的架构。除了管理工具、装载器和虚拟机外,其实重头戏就是HAWQ了。
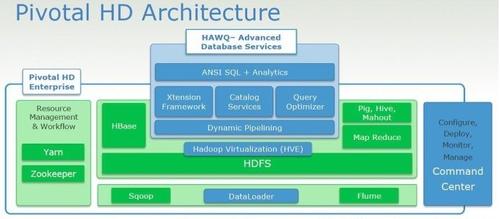
看到这个图你就知道了,所谓的HAWQ就是一个构建在HDFS上的MPP DB。相比Hive、PIG等其他SQL解释器,它有完备的DBMS管理功能,支持标准SQL语法,在性能上更加接近原有DB。
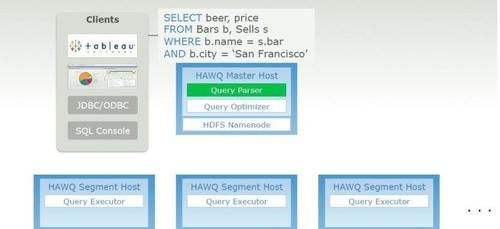
1、基于成本的优化模型。这个很重要,关系数据库的成功很大程度是靠它,基于成本的优化提供了一定的透明性,降低了用户对数据结构的理解。
2、分布式执行器。查询执行通过GPDB(Greenplum数据库)的并行执行引擎(不再使用MR),每次查询开始把数据从HDFS中导入到GPDB,执行过程中通过内存交换数据而非MR(Map Reduce)那样每次任务结束都写磁盘。
3、动态管道技术。这个就是将DBMS执行计划中的流水线移植到HAWQ中来了。这对于交互式SQL查询来说是必不可少的,可以实现秒级反馈,这些是原来Hadoop中不具备的。
4、原来GPDB中的存储是本地磁盘,现在改成HDFS,原来GPDB的单节点的RDBMS只充当执行引擎的功能,不再充当存储引擎功能。
5、GP特有的cost-based parallel query optimizer and planner(基于成本的并行查询优化与规划器)是它的一大优势,也是目前其他大多数的产品中没有的,它能够帮用户选出该SQL最高效的执行顺序。使用GPDB充当执行引擎的好处:标准SQL兼容;支持ACID事务;JDBC/ODBC支持;JOIN顺序优化和索引支持(查询优化器);支持行/列两种存储格式。
6、PXF(Pivotal Xtention Framework)使得HAWQ能够读取存储在HDFS上的任何格式的数据以及存储在其他文件系统和设备中的数据。
其实这些中最重要的就是修改了HDFS上“放置文件”的方式,也就是修改了HDFS文件系统的底层实现,给予了DBMS更大的权限来控制物理文件放置位置。这样才使得HAWQ与外部表的解决方案不一样。除了数据放置的关键技术外,我们对于hdfs文件块的存取进行了native化的处理,性能有大幅度的提升。同时要实现完整的DBMS而不只是一个查询解释器,应该还需要具备并发管理,也就是锁、多版本等一系列的东西;负载管理;权限控制;增量更新等等。这应该是HAWQ对于Hadoop多出来的东西。经过了这些改动,和其他SQL on Hadoop产品的性能和功能对比方面,HAWQ在复杂和深度查询分析上与其他方案相比优势明显。
CSDN:GemFire在互联网领域的主要应用场景有哪些?
刘伟光:GemFire是一个位于应用集群和后端数据源之间的高性能、分布式的操作数据管理基础架构。它提供了低延迟、高吞吐量的数据共享和事件分发。GemFire充分利用网络中的内存和磁盘资源,形成一个实时的数据运算。因此基于网络的,有并发行应用的行为,都能够用到GemFire。它尤其适合需要低延时,高并发的数据访问场景。并能够做广域网的数据同步来实现灾备等高级功能。在解决那些基于高并发OLTP的应用以及基于Web应用的高并发的性能瓶颈问题中,Gemfire无疑是最好的杀手锏!
CSDN:本次发布的新的大数据套件增加了哪些功能?
刘伟光:Pivotal大数据套件2.0版本中包括几种最新数据服务功能:
1.Pivotal CF上的Pivotal大数据套件(Pivotal Big Data Suite on Pivotal Cloud Foundry),利用以领先的“开放云平台即服务”模式运行的应用,提供先进的数据服务功能。
2.Spring XD,高可扩展性的开源分布式框架,面向数据获取、批处理以及数据分析流水线管理。
3.Redis,业界领先的、可扩展的开源键值存储及数据结构服务器。
4.RabbitMQ,领先的可扩展、开源、可靠、面向应用的消息队列。
CSDN:自主可控是2014-15年国内的主旋律。IBM power开源以及和中国本土企业深度合作也打开了另一扇窗。目前国内企业参加ODP有多少(某家电信之外)?对国内特殊情况,ODP会有什么考虑?
刘伟光:其实对于自主可控这边我们是有一些计划的,比如我们正在和国内一些大型本土企业(不方便透漏)计划开展一些深度的合作,不仅仅是协议上的合作,更多的是技术上的开放与授权。同时这也是我们开源的另外一个含义,毕竟开源是没有国界的。目前国内参加ODP的公司还没有,,我们也在积极的寻找有实力有意愿的公司。而在Cloud Foundry开源基金会当中,今年会有一家国内巨头正式加入。。
小结
开源是一个潮流,尽管仍有不足和质疑,但是开源对整个IT行业的带动,对信息技术的推动作用,是无需置疑的。未来云与大数据必将结合得越来越紧密,单独的大数据环境已经逐渐显现出其不足之处,如缺乏足够的弹性和支撑的广度,无法支撑快速的迭代开发等问题。期待ODP的发展可以帮助越来越多的企业得到一栈式的数据服务能力。
 滇公网安备 53230102000482号
滇公网安备 53230102000482号